
So earlier this week, ConvertKit made an excellent post about their AWS bill.
This level of transparency around their bill is, to put it lightly, unusual.
Others have commented extensively (oh hi there Hacker News! What are you doing here? Go back to first principles!) on this, but given that this is what we do for a living here at The Duckbill Group, I figured I’d share my thoughts, too.
In the interest of full transparency and disclosure of my own, Last Week in AWS is a happy ConvertKit customer.
Go read their post; I’ll wait. Back yet? Okay, let’s dive into this.
If they were a client, my initial impressions would be along the following lines.
1. Consider Spot for anything that’s autoscaling
It saves way more than buying reserved instances does, and it also means you have no commitments.
That said, this isn’t necessarily a slam dunk. Any workload that’s comprised of nodes that can’t withstand interruption is absolutely not a candidate for this, but with how much money can be saved here, it’s worth investigating whether an architecture change is worthwhile so you can take advantage of Spot.
2. Reserved Instances
Notice how they describe their clusters in terms of the instance types that exist in them? The i3.2xlarges are their Cassandra and Elasticsearch clusters, their t3.medium nodes are their baseline workers for a bunch of things with intermittent loads, and so on.
Their r4.xlarge instances are instances “they never really needed but were stuck with due to a mistake made while reserving instances last year.”
It doesn’t help now that they’re over with it. But if this happens to you, reach out to AWS support. They’re surprisingly good at helping fix mistakes like this so you don’t have to eat them.
Along that same line, ConvertKit keeps saying “once they figure out their baseline usage they can buy some reserved instances and start saving money.”
Stop that!
If Spot isn’t viable for a workload, go out and buy RIs today.
Worried you’ll overbuy?
Okay, buy 20% of what you think you’ll need, wait a week, and try it again.
3. Let’s talk about those Elasticsearch clusters
ConvertKit mentions having massive volumes of data to search through. I don’t know what their workloads look like, but if they’ve got a bit of latency sensitivity, I’d consider CHAOSSEARCH, out of Boston. This company provides an Elasticsearch-compatible API on top of data that lives in your S3 buckets.
Given that a gigabyte of data in S3 costs 23% of what a gigabyte of data on an EBS volume does, there’s a storage cost win.
But I’m not finished.
By divorcing compute from the storage, they don’t have to manage the crappy parts of Elasticsearch—by which I mean “all of it.” Based upon what I’ve seen, they’d likely cut their Elasticsearch bill by something like 80% after paying CHAOSSEARCH, but it’d require a bit of investigation.
In the interest of continued transparency, CHAOSSEARCH sponsors my podcasts and newsletters. But, truth be told, I’ve been recommending them long before that happened. I have no partnerships with any vendor in the cloud space; if I recommend a product, it’s because it’s what I’d use if it were my environment.
4. ConvertKit waited on a C4 –> C5 migration until RIs ran out
Never do this!
If you’re letting a sunk cost dictate what you do architecturally, you’re hamstringing yourself in most respects. People’s time is worth more than what you spend on infrastructure. If there’s a capability gap, fill it; don’t wait for instances.
If you want to avoid having to have this debate, go for three-year convertible RIs; all you’re committing to at that point is using some amount of EC2 in a particular region.
You’re not bound to any particular instance families. Given that there are roughly 200 different instance types in us-east-1 alone, this is the most flexible path. It offers better discounts than a one-year standard reserved instance does.
5. Beware the Managed NAT Gateway
Oh, honey. Don’t use this terrible service for anything at scale.
“We’re sending 1.1TB of data per day through our NAT Gateway,” ConvertKit says.
Of course, they’re paying data transfer costs on this data (depending on where it’s going, that’s anywhere from 0¢ to 9¢ cents a gig, under the Data Transfer section of the bill), *plus* 4.5¢ per gig in data processing fees.
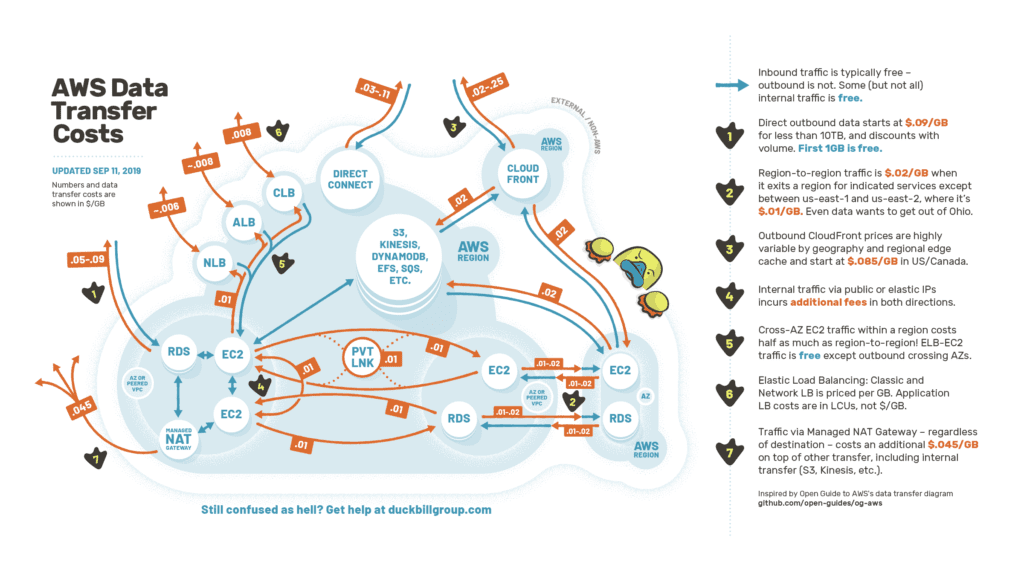
Replace these with NAT instances you manage yourself (or move the workload to a public subnet) and that 4.5¢ charge vanishes. Voila.
Plus, if they haven’t configured gateway endpoints for S3, anything they write there passes through the gateway, too. That’s right, it applies to data destined for other AWS services!
This is incredibly complicated—but borderline abusive from a billing perspective.
6. Enable S3 Data Analytics
Go into the largest S3 buckets and turn on S3 analytics.
In only three short months, it will start spitting out recommendations around tiering changes, unlocking sensible S3 infrequent access lifecycle policies that save money.
The rest of this section is largely around data transfer. I’d want to delve deeper before making additional recommendations, but there’s almost always an optimization story here. There’s just not enough information in their post to comment intelligently past that point.
Aside: The RDS RI model is bonkers
This is the part of the post where I take AWS behind the woodshed for their horrible reserved instance model.
ConvertKit just bought RIs in July. AWS is pretty clearly incentivized to drive business away from traditional MySQL databases and over to Aurora, their flagship database named after a Disney princess. They crow about it breathlessly in virtually ever conference keynote they give.
This is fine. But because of their RI model, if ConvertKit would benefit from an Aurora migration (and while it’s highly workload dependent due to their 20¢-per-million-IO-operations, statistically they’d lower their RDS bill significantly), they wouldn’t consider it until next July at the earliest because they’d be leaving RI money on the table if they did.
Smooth, AWS. Real smooth.
Final Thoughts
A few other thoughts that struck me about their environment, but I don’t have enough detail about their environment to do a proper analysis:
- ConvertKit may want to take a look at what regions they’re in. If they can get by with us-east-1 and us-east-2 as their two regions, cross-region data transfer is half-price between them, as even data wants to get the hell out of Ohio. Capitalize on that.
- If ConvertKit goes with Spot, they’re not going to want to use t3 instances due to economic reasons. The t3 instance type starts with a depleted CPU credit balance, so that’d cost way too much money when they exceeded the baseline.
- Look at ConvertKit’s historical usage of AWS Support. If they’re getting value from it, by all means keep it. If not, turn it off. They can always turn it back on later.
- I’m suspicious of ConvertKit’s CloudFront bills. It may be time for a quick call to Fastly, CloudFlare, etc. to see if there’s a compelling alternative.
To sum up, ConvertKit has done a fine job and they deserve a round of applause for the transparency. None of this stuff is easy, and there’s an incredible depth of complexity here. I can’t fault them for missing a few things, given how complex this gets.
They’ve built a successful, thriving business. They just have a few things they could do to optimize their bill. And the truth is it wouldn’t even require that much work.
If you’ve found yourself with a horrifying AWS bill and confused about fixing it, let’s chat. We see dozens of these a year and we’re happy to help. You can learn more about our consulting here.




