
In the past, if you wanted to ask questions about data, you had to copy that data into a database. As data sets get bigger and bigger, managing those databases becomes more work and requires more expertise. Of course, it’s possible to administer your own data infrastructure. It just takes a lot of time and effort.
Amazon Athena is an interactive, serverless query service that cuts out this overhead. It lets you ask questions about data stored in S3 using familiar SQL queries, with no infrastructure to manage. You log in, select the data, run a query, and get results. It can analyze petabytes of data directly from S3, and queries return within seconds or minutes.
Common use cases for Athena include analyzing log files from CloudFront and similar services, ad hoc exploration of analytics data, and experimenting with new data sets.
What are the benefits of Athena?
Like many AWS services, Amazon created Athena to solve challenges their customers were facing. They saw customers wanting to analyze data in S3 who ran large and expensive EMR clusters. A lot of people were building similar plumbing and running similar infrastructure. But what they really wanted to do was data analysis—not database administration.
Amazon built Athena to make it easier to query data in S3, and it has several benefits:
Athena is serverless—Amazon manages all the compute infrastructure, so you don’t have to. What do we mean by that? You don’t have to spin up a cluster, manage capacity, or load data. Instead, you just run queries and the data is read directly from S3.
Athena can be cheaper than similar services—you only pay for the queries you run. If you’re not running a query, you don’t pay anything. This can be a significant saving over a service like EMR, where you pay for compute instances whether or not you’re doing anything.
Athena uses standard SQL for queries—so it’s accessible to a wide audience. Not everyone knows how to use a Hadoop cluster or a data lake, but lots of people have data in S3 and know how to write a SQL query. In particular, SQL is widely used among business analysts; Athena is for more than just developers and engineers.
How does Athena work?
You start with data stored as objects in S3. Data can be in a variety of structured or semi-structured formats, including plaintext files like CSV and JSON, application and AWS service logs, and columnar files like Apache Parquet and Apache ORC.
After your data is squared away, you create a table in Athena. This includes a schema (i.e., how the data is organized) and a location (i.e., where the data lives in S3). But it doesn’t contain any data itself. Tables are defined using the Apache Hive DDL, which looks a lot like SQL.
Finally, you write a query in standard ANSI SQL and run it. The query will be parallelized and distributed across hundreds or thousands of cores in a pool of Amazon-managed compute. Those cores read the data directly from S3, perform the query, and return the results. Athena uses Presto, an open-source distributed SQL engine designed for petabyte-scale queries.
There are three ways to use Athena:
- The AWS Management Console has a built-in SQL editor, a wizard for creating schemas and tables, and it displays results inline. It’s a good way to get started.
- Athena has ODBC and JDBC drivers, so you can connect to it with your favorite database app or library.
- The Athena SDK has an asynchronous API. You run a query and get back a unique ID, and then you use that ID to monitor progress and retrieve results.
Athena keeps a history of all the queries you’ve run, and it saves the results to CSV files in S3—ready to be used as part of a larger pipeline.
How does Athena fit into Amazon’s other big data services?
Athena is an interactive query service—not a general purpose database. It’s meant for answering questions quickly, with zero infrastructure—not being a full data processing service.
If you want to visualise your data, consider QuickSight. It’s a visualization tool that can pull in data from a number of sources, including Athena, EMR and Redshift, allowing you to build interactive visual queries and dashboards.
If you want more fully-fledged ETL data warehouses, look at EMR and Redshift. They offer large-scale, distributed data processing that goes beyond just queries, including more complex transformations and machine learning. These can be faster than Athena, but that speed and flexibility comes at a cost. For example, there’s more upfront work to create a database cluster and load your data, and they can be more expensive to run, too. Unlike Athena, you’re managing and paying for all the compute power—even when it’s sitting idle.
Amazon’s big data services can share data, and the lines between them can get blurry. You don’t have to pick just one service. You could use a mixture, with Athena for simple queries, EMR for more complex ETL work, and QuickSight for visualization.
Athena is to EMR what Lambda is to EC2. There are limitations, but if your use case fits within them, the serverless approach gives you something incredibly powerful that can be much easier and cheaper to run.
How do I try Athena?
The best way to try Athena is using the AWS Management Console. When you open Athena for the first time, you’ll see a three-pane interface that may look familiar if you’ve used other SQL editors:
On the left, there’s a list of databases and tables. (In Athena, a database is just a way to group tables.) On the right, there’s a SQL query editor and a results pane.
First, you need to tell Athena where to save your results. Athena saves the result of every query to S3, and you need to tell it which bucket and folder to use. Either click the link in the blue “Before you run your first query” banner or click the Settings tab in the top bar.
After that, I’d suggest working through the interactive tutorial by clicking Tutorial in the top bar. This is similar to the Getting Started Guide, but it runs entirely in the Console and highlights the important Console features in-place.
In the tutorial, you point Athena at some ELB log files, create a table and schema, and run an initial query to sample the data. Log analytics is a very common use case for Athena—it can query logs from CloudFront, ELB, and a variety of other services.
The query results are shown in a table, or you can download them as a CSV:
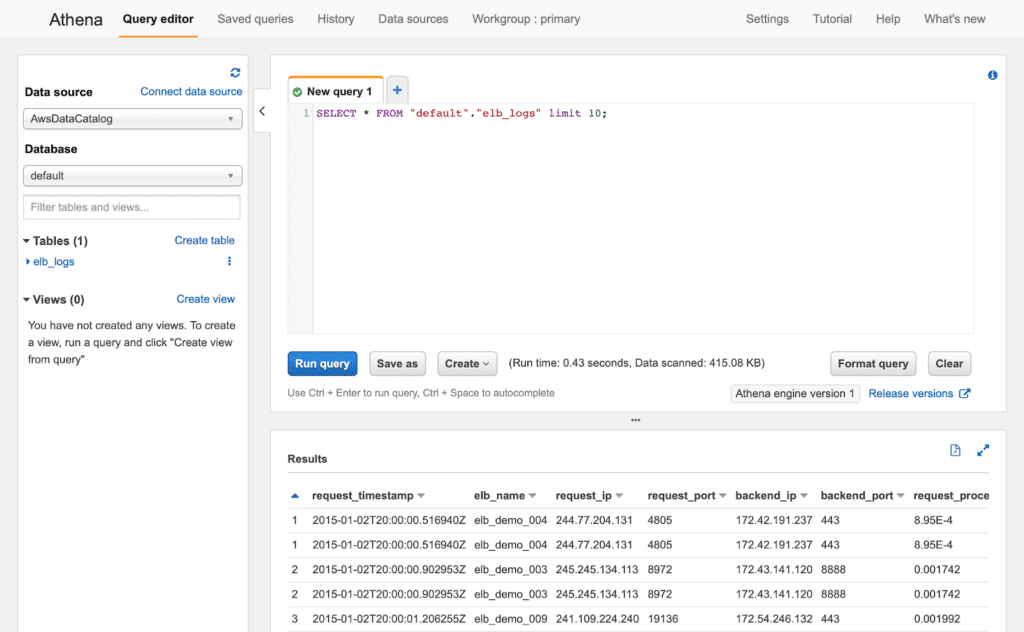
You can write more complex queries to get a feel for Athena before you load in your own data. For example, you could look for slow requests (what’s the highest request_processing_time?) or chatty clients (what’s the most common request_ip?).
What does Athena cost?
Athena pricing only has one variable: how much data it needs to scan to run a query. Every time you run a query, Athena has to scan all the relevant data from S3, and Amazon charges you $5 per terabyte scanned. The more you scan, the more you pay. Aside from the S3 storage, this scanning is the only cost of using Athena. This means that if you don’t run any queries, you don’t pay anything.
This can make Athena very price competitive against more traditional databases. Rather than paying for an always-on pool of compute, you just pay for the queries you run. You’re not paying for instances that are often sitting idle.
This also makes Athena safe to try. You can play with it, run a few test queries, and if you don’t like it, walk away. You’re not going to get a surprise bill for an experiment you forgot to turn off.
How do I get the best Athena performance?
Athena has to scan all the data it needs for a query at query time, so you can make queries faster and cheaper by reducing the amount of data it has to scan. Here’s how you can do that:
- Compress your files. Athena can read compressed formats like gzip, zlib and Snappy. If you compress your files, Athena scans fewer bytes for the same data.
- Use columnar file formats. Athena can read formats like Apache Parquet and Apache ORC, which organize data by column rather than row. If you’re only interested in a subset of columns, these formats make it easy for Athena to skip reading the unwanted columns.
- Partition your data. Like columns, partitions organize your data into chunks that are likely to be read together. For example, CloudFront logs are partitioned by date because you often want to look at logs from a specific time. Athena can skip scanning partitions you’re not interested in.
These changes can make a dramatic improvement to query speed and cost, sometimes by multiple orders of magnitude.
Should I use Athena?
Do you have a pile of data in S3? Do you want to ask questions about that data? Do you know how to express questions as SQL queries? If so, Athena is aimed at you.
An interactive query service can be used in all sorts of ways, and it’s easier to manage than running a full-featured data warehouse. If you have some data you want to analyze, Athena can be a great starting point.
That said, AWS has a ton of services, and figuring out the right ones to use can be an incredibly tricky undertaking.
Need some help picking the best solutions for your use case? We’ve got you covered.




