
Once upon a time, file storage meant your filing cabinet. In some ways, today’s file storage is very different — and in others, it hasn’t changed at all.
File storage is a system for keeping data in an organized hierarchy of files and folders. You can share that hierarchy across a network, so multiple people can work on the same collection of files. It’s one of three major types of cloud storage, alongside block storage and object storage.
This post is the second in a three-part series to look at how each of these cloud storage technologies work, what they’re good for, and how to use them. Let’s dive into file storage and how it lets us share data at a distance.
How does file storage work?
File storage is probably what you’re used to: You put files in folders, and folders in other folders, and so on, until everything is arranged into a hierarchy. This is a metaphor that comes from the world of paper files, manila folders, and filing cabinets.

Each file has a path, which tells you where to find the file. You use the path to read and file, and folders help you keep your files organized.
Individual files can have some file system-defined metadata, such as who the owner is, the last time the file was modified, and who’s allowed to read it. The metadata scheme is fixed, and there’s not much you can do to change it.
So far, this is like using a file system with a block storage volume on my local machine. What if I want to work on files with other people?
You can share a file system over a network, but now we need to coordinate activity between different users. It’s fine if two people want to read the same file, but what if they both want to write to the same file? We need to coordinate writes between different users.
Typically, file storage coordinates multiple writes by using some form of locking. For example, it might lock files to individual users so that only one person at a time can write to a file.
Suppose I have some file storage I’m sharing with my Last Week in AWS colleagues. I’m working on this article, so the file is locked for me — I’m the only one who’s allowed to make changes. Everyone can still read the file, but nobody else is allowed to modify it.
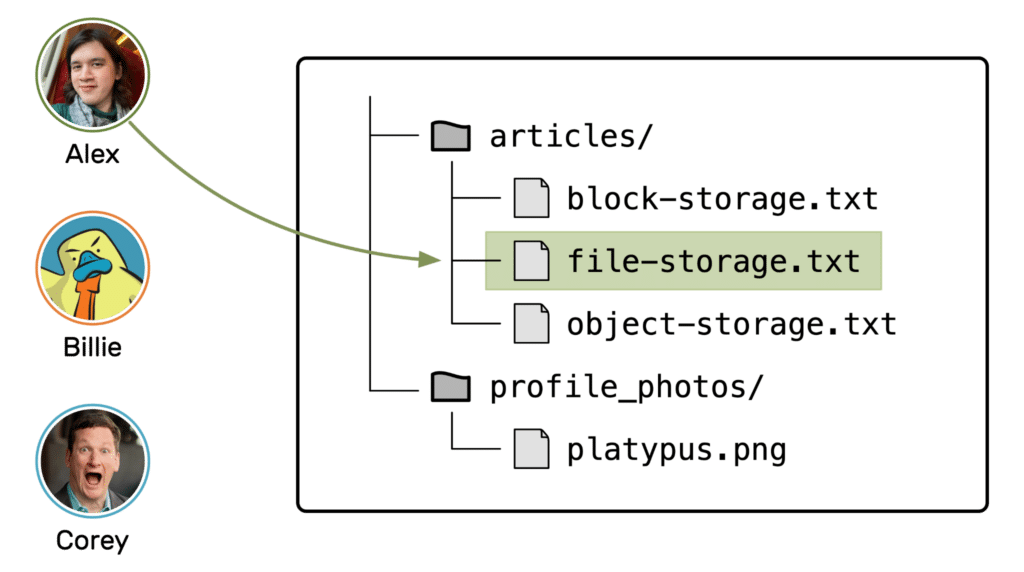
But because the file storage has only locked this single file, Billie the Platypus and Corey can still work on different files. If Billie wants to upload a new profile photo, he can save it to the “profile_photos” folder. The file storage locks that file to him, and that’s OK, because we’re not working on the same file.
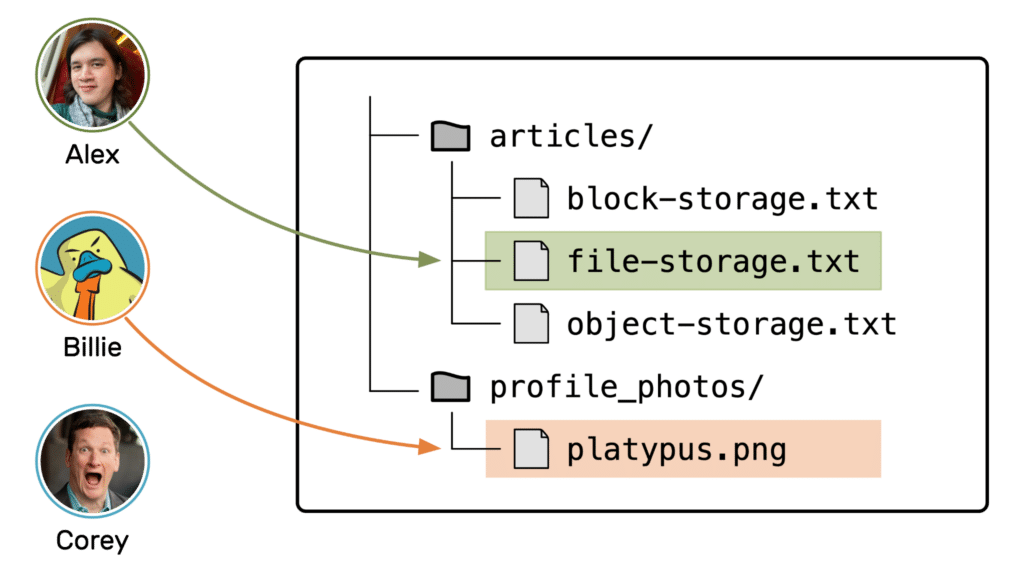
But now if Corey wants to upload a different photo of Billie, he can’t. The file is locked to Billie, and nobody else can write to it.
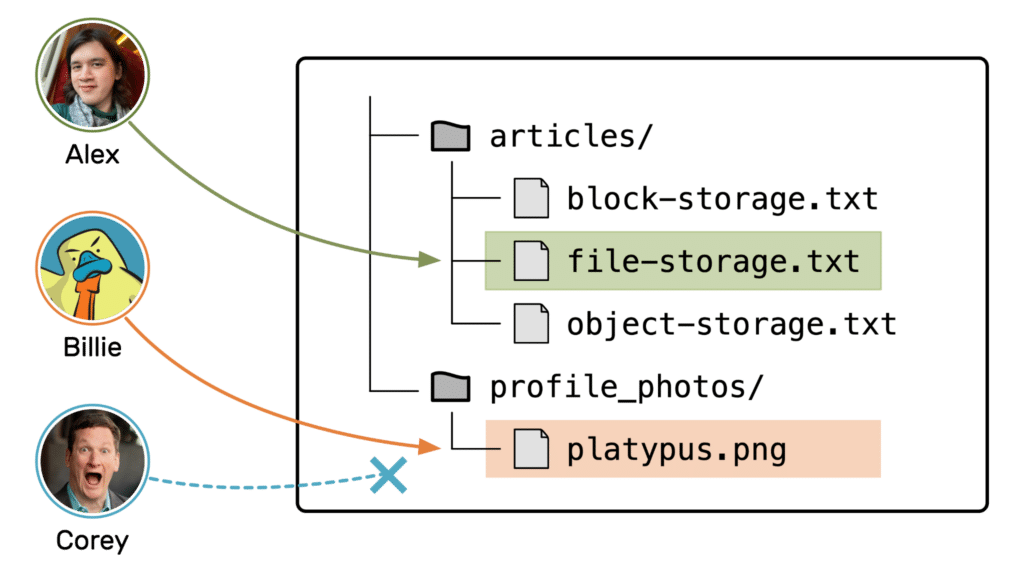
Corey can save his photo to a different file, or he can wait for Billie to finish working on his photo and the file to be unlocked. The file storage prevents two simultaneous writes to the same file, which could cause file corruption or other weirdnesses.
The specifics of file locking vary between implementations, but that gives you the general idea. File storage uses locking to ensure that multiple users can work on the same collection of files, without getting into conflicts.
What’s file storage good for?
File storage is great when you have files you want to share among a lot of users or machines and you don’t need the highest possible performance.
This form of cloud storage is handy for a wide variety of workloads, too. You might have encountered file storage at your workplace. Services like Microsoft SharePoint and Microsoft OneDrive present a form of file storage, and they’re used for all sorts of files. Business documents, shared videos, datasets for analytics … the list goes on and on.
When shouldn’t I use file storage?
File storage starts to break down when you scale it up. Current implementations can scale to thousands of users and millions of files — but it can only scale so far. The file storage has to track the file hierarchy and the file locking. At some point, it becomes too large to be manageable, and performance degrades until it’s unusable.
It has a performance penalty when compared with block storage. Both the latency and the lack of block-level granularity mean that working with networked file storage isn’t as fast as working with a locally attached block storage volume. For the highest-performance workloads, like databases or transactional workloads, it’s a poor choice — but in most other cases, it’s fine.
How do I get file storage?
There are plenty of providers of cloud file storage, including Amazon Elastic File System (EFS), Azure Files, and GCP Filestore. They use protocols like NFS and SMB — the same as you might use in your on-premise data center.
File storage has more dimensions to configure. You typically have to choose some combination of file protocol, volume size, and throughput, but the details vary between providers. For example, Amazon EFS will grow or shrink the size of your file storage to match the data you’re storing, whereas other file storage providers want you to pick volume size upfront.
There’s no easy way to know how much throughput you’ll need. Different workloads will need different throughput, based on the number of clients and the amount of data they’re sending. Play with the numbers to see how it affects performance.
Pricing varies a lot, but I’d typically budget $100–$200 per TB per month.
File storage, in a flash
File storage is great for sharing files among lots of clients. It has room to scale, and it’s suitable for a wide variety of workloads.
It’s not so good if you want peak performance or massive scaling. For those, you might be better off with block storage or object storage.
Compare cloud storage types using the other two articles in our series: block storage and object storage.




